








Evropa podle AI – vítejte v zemi Mookie
Nedávno na Redditu vyšel zajímavý příspěvek nazvaný „Asked ChatGPT to make a map of Europe“, tedy požádal jsem ChatGPT o vytvoření mapy Evropy. Výsledek byl, mírně řečeno, bizarní. Mapa byla tak chybná, že to hraničilo s absurditou – snad všechny názvy evropských zemí byly napsané špatně. Na mapě se objevily neexistující státy:
- „Zormany“
- „Yoland“
- „Eeland“
- „Mookie“ (což mělo být Turecko)
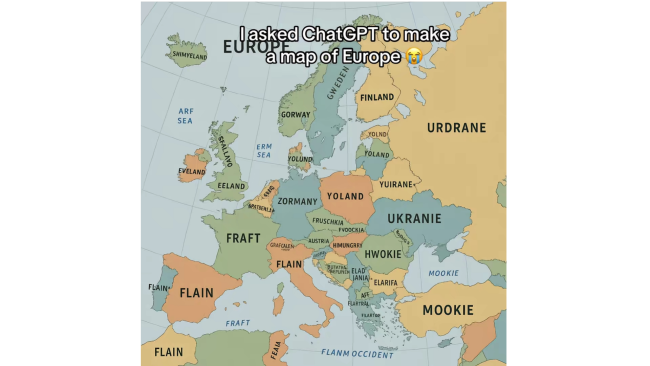
Zdroj: Reddit

Zdroj: Reddit
Bizarní geografické přešlapy
Když server Cybernews požádal ChatGPT o vytvoření mapy Evropy, výsledek na první pohled vypadal pro netrénované oko celkem věrohodně. Při bližším zkoumání však bylo zřejmé, že Anglie byla zcela vynechána a místo ní se rozprostíralo Irsko.
Krym byl navíc vybarven jako součást Ruska, což je samozřejmě závažný problém. Dánsko vypadalo, jako by se psalo podobně jako demence, a Švýcarsko bylo téměř nečitelné. V další verzi už byla Anglie zahrnuta, ale chybělo Nizozemsko a Island byl nesprávně označen jako „Icland“.
Zdroj: Vygenerováno v ChatGPT, redakce
Zdroj: Vygenerováno v ChatGPT, redakce
České mapy podle AI
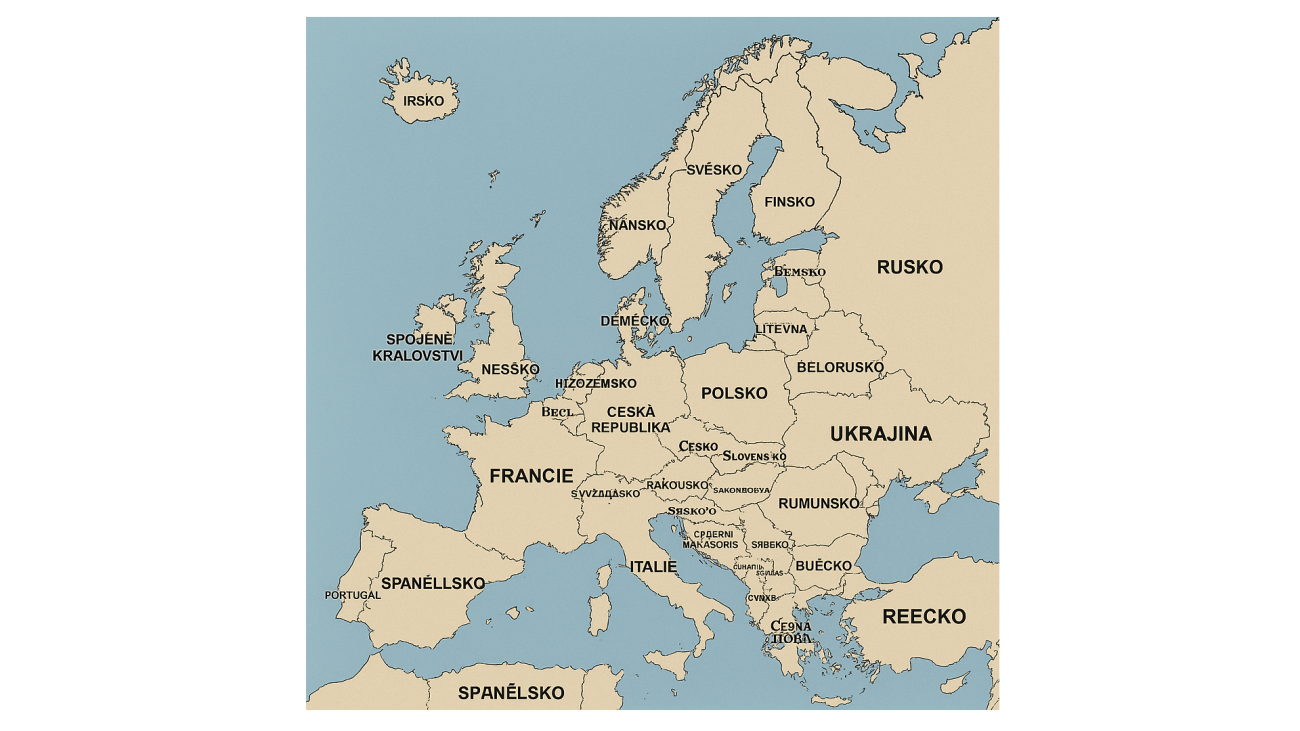
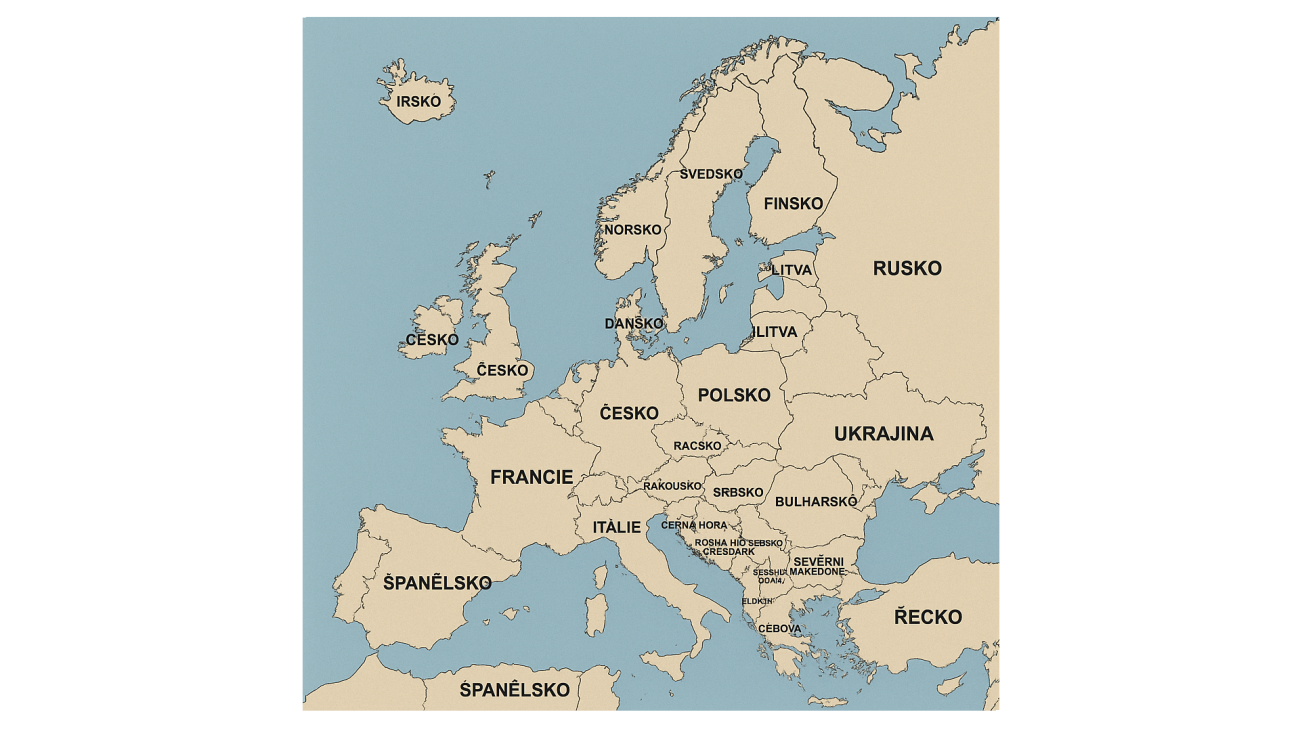
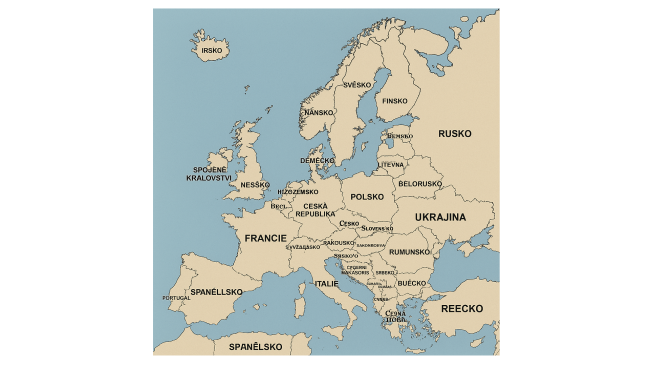
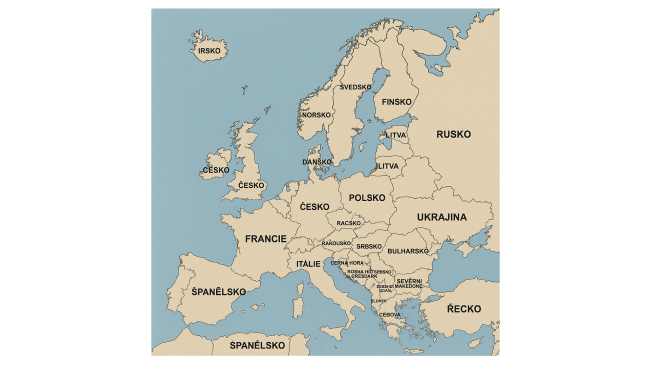
Zajímalo nás, jaké pěkné „české“ názvy států umělá inteligence do mapy zakreslí. Výzva zněla jednoduše: „Nakresli mapu Evropy a použij české názvy zemí“. Českou republiku chatbot ChatGPT v první iteraci ještě zvládl docela dobře. Ale pobavili nás státy „Litevna“ (patrně Litva), „Nansko“ (Norsko), „Hizozemsko“, nebo „Buecko“.
Ani po upozornění, že názvy nejsou dobře, se ChatGPT moc nepochlapil. Název Česko se mu zřejmě zalíbil, takže ho umístil do Velké Británie, Irska a Německa. Území náležící Česku přitom označil jako „Racsko“.
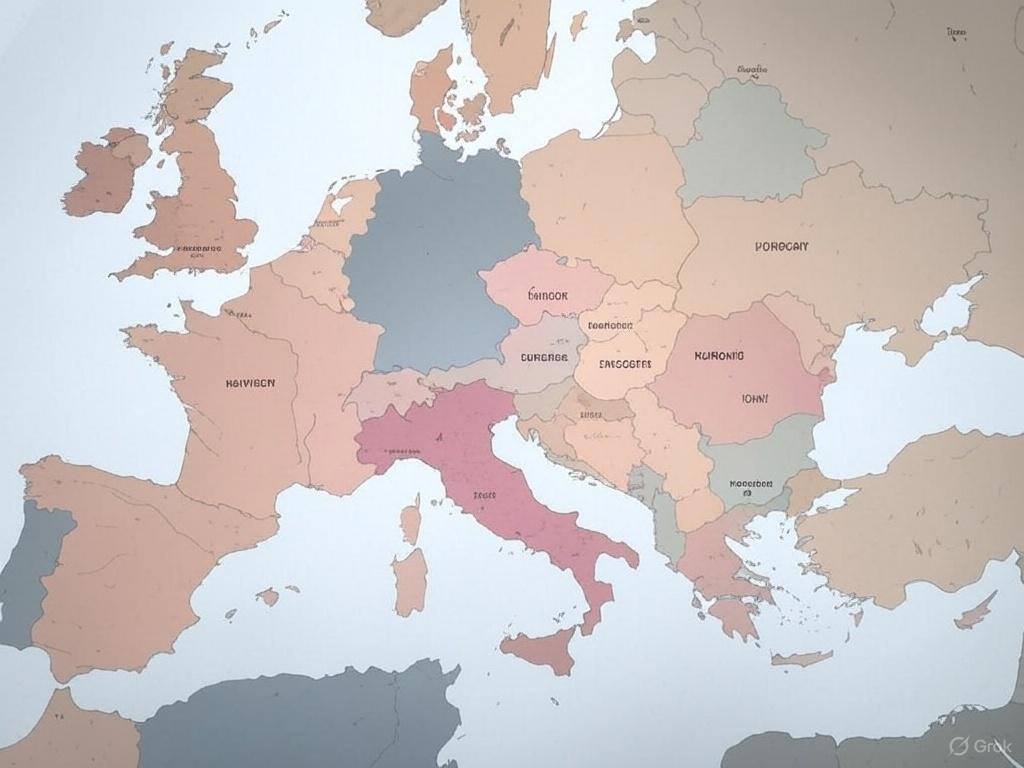
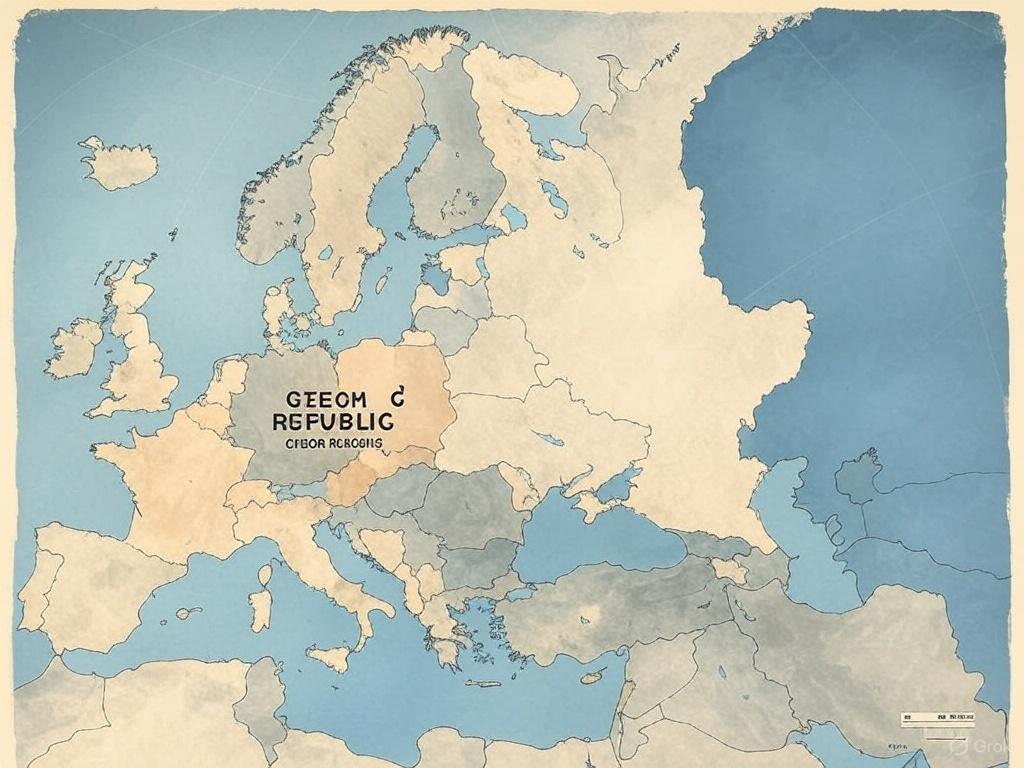
V této disciplíně si ale lépe nevedou ani konkurenční platformy Midjourney, Gemini od Googlu a Grok vyvinutý společností xAI Elona Muska. V jejich mapách se názvy států v mnoha případech ani nedají přečíst.
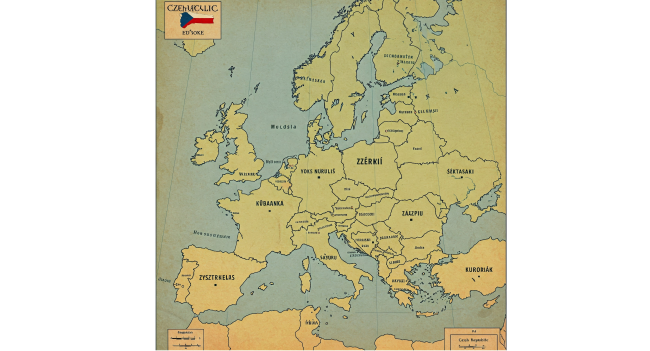
Zdroj: Vygenerováno v Gemini, redakce
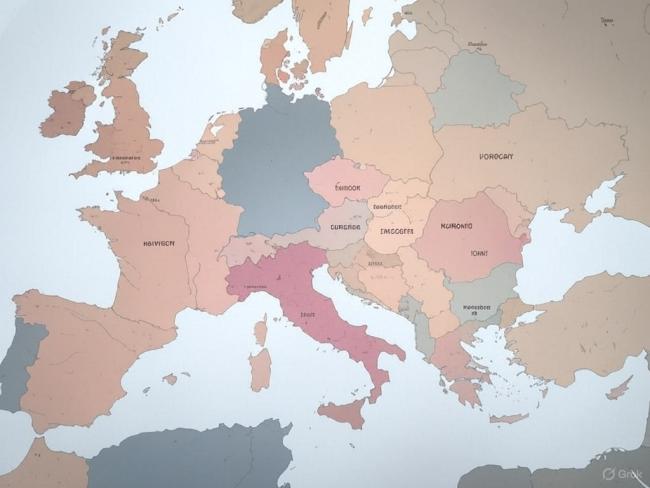
Zdroj: Vygenerováno v Grok, redakce
Proč AI neumí správně psát?
Taková selhání vyvolávají otázku: proč ChatGPT nedokáže správně hláskovat? Možná si vzpomenete na aféru „Strawberry Gate“, kdy ChatGPT a mnoho dalších AI modelů nedokázalo určit, kolik písmen R je ve slově „strawberry“. Ale případ s mapou Evropy je také zajímavý.
Tyto modely kvůli architektuře LLM pracují spíše s tokeny, než s jednotlivými písmeny. Teka Hadgu pro TechCrunch řekl, že algoritmy jsou nastaveny tak, aby vytvářely něco podobného datům, na kterých byly trénovány. Neznají ale pravidla jazyka.
Podivné mapy a chyby v pravopisu představují jen část problému. Současné AI systémy trpí řadou dalších nedostatků. To limituje jejich praktické využití.
Jedním z největších problémů je tzv. „halucinace“. Jde o situace, kdy AI s naprostou jistotou uvádí neexistující fakta, cituje neexistující studie nebo vymýšlí detaily, které nikdy nebyly součástí trénovacích dat. Uživatelé bez dostatečných znalostí v oboru mohou tyto halucinace přijmout jako fakta.
Mohlo by vás zajímat

Další nedostatky umělé inteligence
Některé AI systémy mají své znalosti „zmrazené“ k určitému datu. Neví tedy nic o novějších událostech. To znamená, že nemohou poskytnout aktuální informace o proběhlých volbách, přírodních katastrofách nebo objevech.
AI také selhává v oblasti „zdravého rozumu“ a logického uvažování. Dokáže skvěle formulovat odpovědi na základě statistických asociací, ale nedokáže vyvodit jednoduché logické závěry. Modely umělé inteligence také často postrádají kulturní odlišnosti a jemné nuance jazyka. Ironie, sarkasmus a humor jsou oblasti, kde umělá inteligence často tápe.
Nástroje umělé inteligence mají také problémy s etikou a morálkou, můžeme-li to tak nazvat. Přestože jsou vybaveny různými bezpečnostními mechanismy, ty často selžou. AI se pak chová podivně. Navíc mohou neúmyslně zesilovat společenské předsudky .
Stále jsme tedy daleko od inteligence v lidském slova smyslu. A právě proto by měl každý uživatel přistupovat k výstupům AI se zdravou dávkou skepse. Lidský úsudek, znalosti a kritické myšlení zatím zůstávají nenahraditelnými schopnostmi. Platí to především v době, kdy se informační prostor stále více plní obsahem generovaným umělou inteligencí.
Zdroj: Reddit, Cybernews, TechCrunch
Mohlo by vás zajímat

Článek obsahuje prvky vygenerované AI




